Build a Large Language Model (From Scratch)
Book companion hub
If you want to understand LLMs beyond API calls, the best way is to build one from the ground up. Build a Large Language Model (From Scratch) walks through text embedding, attention, GPT-style model architecture components, pretraining, and finetuning in Python and PyTorch.
Also: Amazon book · Manning course

Study Guide
Start with the chapter
Read the chapter first so the implementation has context. I recommend doing a first read-through pass without coding at first.
Open book pageUse video as an optional second pass
Use the video course after reading if you want the same implementation ideas explained in a different format.
Open video playlistBuild alongside the book chapter
Retype and run the code after reading each chapter for the best (but most time-intensive) learning experience. Otherwise, execute the notebooks cell by cell and edit small parts when you want to explore an idea. (I have some more tips on reading books here, if you are interested)
Open code repositoryUse the exercises as the check
Try the exercises at the end of each chapter before looking at the solutions. The exercises help self-check whether you understood the chapter implementation.
Feedback
See book page for more testimonials.
"If you want to become a top-tier ML / AI Engineer, you need to understand what's going on under the hood."
"I got a serious closeup look at what goes on inside an LLM."
"This is the best technical book I have ever studied by a large margin."
"Ultimate hands on guide to build foundational models. This is the book you want to buy if you want to go deep."
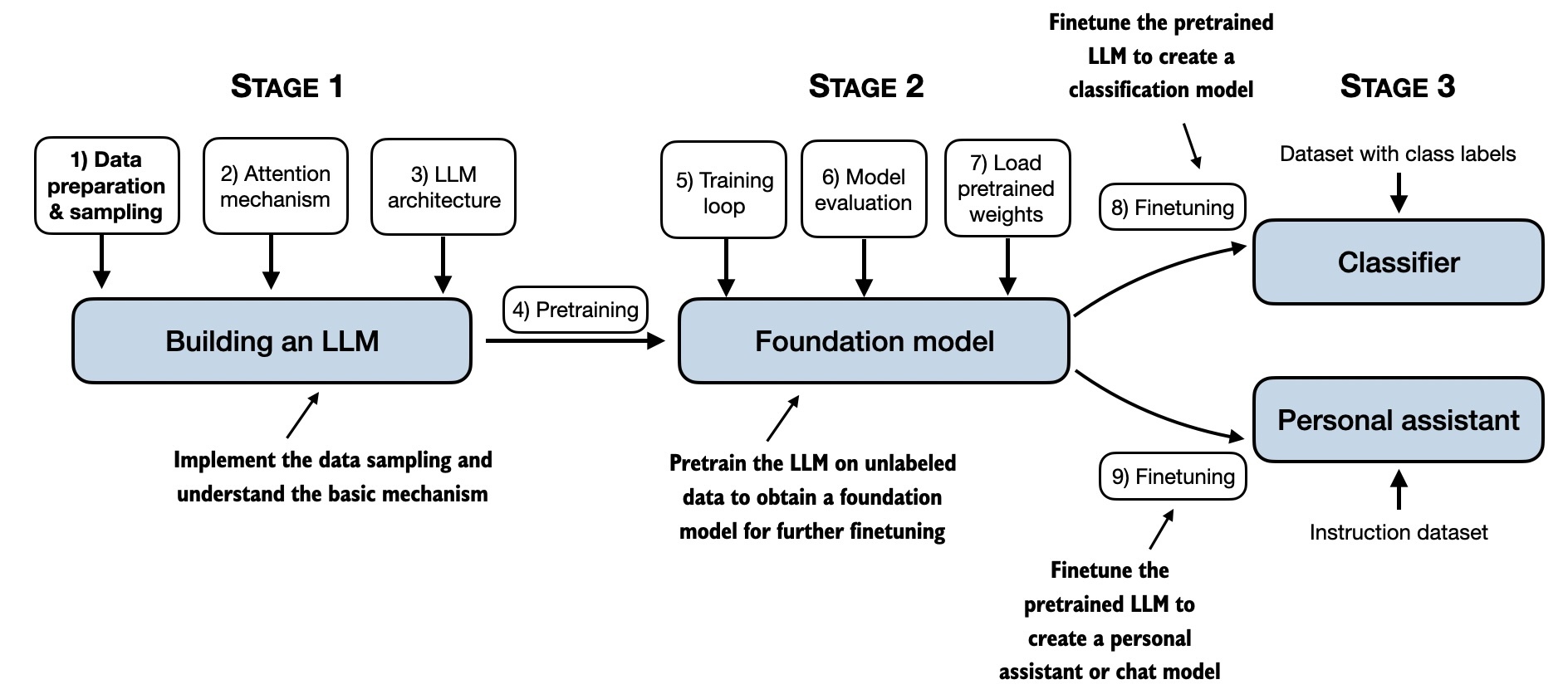
Chapter Map
| Chapter 1 | High-level orientation to LLMs and the model-building path. | Open Chapter 1 code |
| Chapter 2 | Text data, text embedding, byte pair encoding, and input-target construction. | Open Chapter 2 code |
| Chapter 3 | Self-attention, causal attention, multi-head attention, and transformer blocks. | Open Chapter 3 code |
| Chapter 4 | GPT model implementation plus modern architecture concept guides. | Open local concept guides |
| Chapter 5 | Pretraining, loss functions, text generation, sampling, and model loading. | Open Chapter 5 code |
| Chapter 6 | Classification finetuning and using a pretrained LLM for a supervised task. | Open Chapter 6 code |
| Chapter 7 | Instruction finetuning, prompt formatting, and instruction-following behavior. | Open Chapter 7 code |
| Appendix A | Introduction to PyTorch, including notebook code and distributed training notes. | Open Appendix A code |
| Appendix B | References and further reading for the main chapters. | Open Appendix B resources |
| Appendix C | Exercise solutions for checking the chapter implementations. | Open Appendix C solutions |
| Appendix D | Training-loop additions such as learning-rate schedules and other practical refinements. | Open Appendix D code |
| Appendix E | Parameter-efficient finetuning with LoRA. | Open Appendix E code |
Architecture Concept Guides
The book covers the core implementation path through text embedding, attention, GPT-style model architecture components, pretraining, and finetuning. The concept guides below are advanced follow-up material for connecting those basics to current model architectures, memory use, and serving tradeoffs. They are best read after completing the book.
A Visual Guide to Attention Variants in Modern LLMs
Use this article for a visual pass through MHA, MQA, GQA, MLA, sparse attention, sliding-window attention, and hybrid designs.
Read the articleMoE and SwiGLU
Use these guides to connect sparse expert routing and gated feed-forward layers to model capacity and inference cost.
Open MoE explainerThe Big LLM Architecture Comparison
Use this guide to compare current decoder-style LLM architectures, including normalization, position handling, attention choices, and MoE layers.
Read the guideRelated From-Scratch Articles
These articles are optional follow-up reads for specific implementation details. They are best read after completing the book.
Self-Attention from Scratch
A compact standalone implementation of the core mechanism behind transformer LLMs.
Read the articleBPE Tokenizer from Scratch
A practical implementation of byte pair encoding, one of the first pieces to understand before LLM training.
Read the articleKV Cache from Scratch
A focused explanation of the inference cache that makes autoregressive generation efficient.
Read the articleQwen from Scratch
A bridge from the book's baseline implementation to a modern open-weight model family.
Read the articleLoRA and DoRA from Scratch
A code-oriented path into parameter-efficient adaptation after you understand the base model.
Read the articleLLM Evaluation from Scratch
Benchmarks, verifiers, leaderboards, and LLM judges as practical tools for checking model behavior.
Read the articleWhere to Go Next
After finishing the book, these are the next places I would go. Continue with reasoning methods, or use the gallery to compare current model architectures more broadly.
Build a Reasoning Model (From Scratch)
Continue here after the LLM basics if you want inference-time scaling, reinforcement learning, and distillation.
Open reasoning hubLLM Architecture Gallery
Compare architecture figures, attention mechanisms, decoder types, and implementation links across model families.
Open gallery